The specification of how modern Nvidia GPUs are organized and execute programs.
Intentionally analogous to the CUDA programming model.
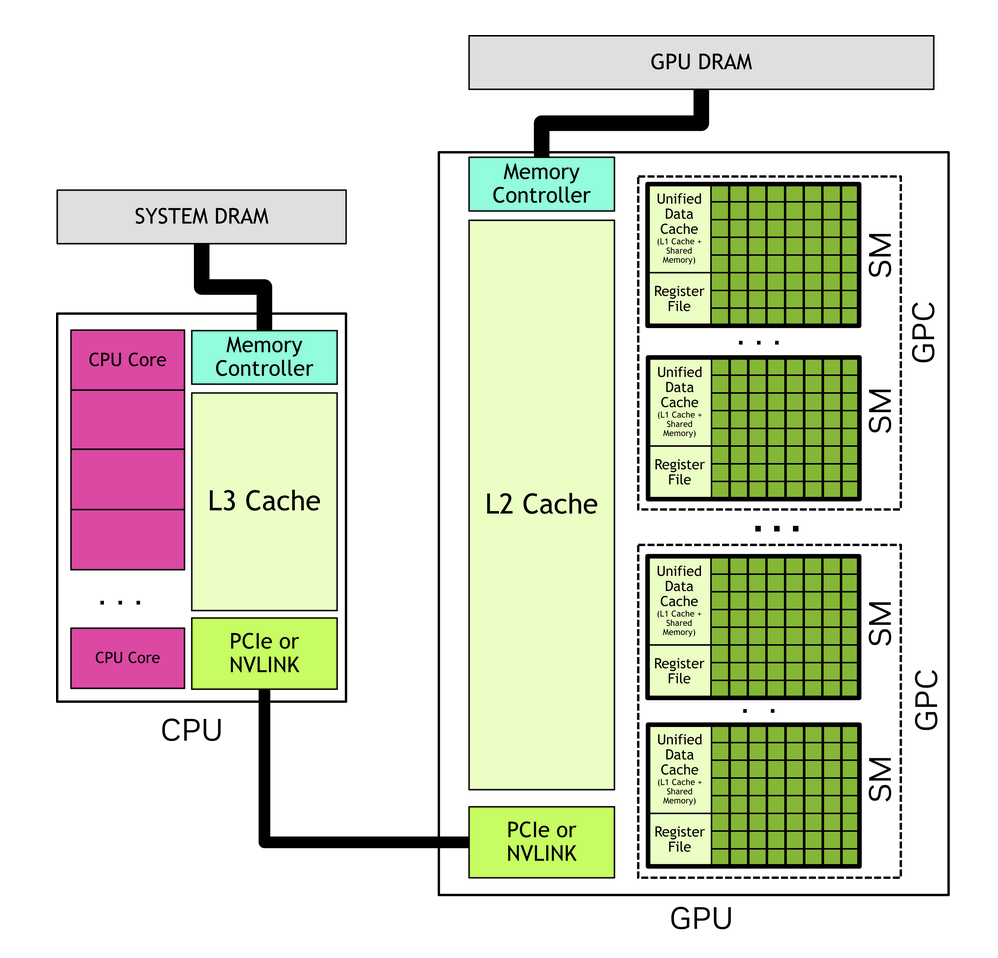
We’ll use Nvidia architecture and terminology, but generalize across Nvidia’s architectures.
NVIDIA GPU (generic)
├── External Interfaces # To PCIe or NVLink
│
├── Memory Controllers (HBM/GDDR) # To HBM or GDDR
│
├── L2 Cache # Hardware-managed, global, sliced
│
├── On-Chip Interconnect # Connects SMs, L2/memory, and external
│
├── Work Distributor / CTA Scheduler # Assigned thread blocks to SMs
│
└── GPCs (Graphics Processing Clusters)
└── SM Clusters # Also historically called TPCs
└── SMs (Streaming Multiprocessors)
├── Unified L1/Shared Memory # Partitioned into either a
│ ├── L1 cache # hardware-managed cache, or
│ └── Shared memory # software-managed scratchpad
│
├── Register File
│
├── SM Subpartitions # Typically multiple per SM
│ ├── Warp Schedulers
│ ├── CUDA Cores # FP/INT ALUs
│ ├── Special Function Units (SFUs) # Hardened units for transcendental ops
│ └── Load/Store Units # Issues memory operations
│
└── Tensor Cores # Matrix math units